Optische Zeichenerkennung (OCR)

![]()
![]()

Optische Zeichenerkennung (OCR) beinhaltet die Umwandlung eines Bildes mit Text in ein Format, das eine Maschine interpretieren kann. Wenn Sie ein Textdokument scannen, speichert der Computer es als Bilddatei und verhindert so direkte Textbearbeitung oder Suche. OCR ermöglicht die Umwandlung des Bildes in Text.
OCR aktivieren
OCR sollte standardmäßig aktiviert sein. Falls dies nicht der Fall ist, können Sie es im Konfigurationsbildschirm, unter dem Abschnitt "Allgemein" aktivieren. Wenn Sie dies tun, wird Joplin Ihre Bilder (PNG und JPEG) und PDF-Dateien scannen, um Textdaten daraus zu extrahieren.
Das Scannen von Dokumenten ist nur in der Desktop-App verfügbar, da dies ein relativ ressourcenintensiver Prozess ist. Die mobile App hat über die Synchronisierung Zugriff auf diese OCR-Daten.
Bisher ist OCR zuverlässig beim Scannen von gedruckten Texten, insbesondere PDFs oder Bildern, bei denen der Text klar ist, wie z. B. Screenshots. Derzeit unterstützen wir keine handschriftlichen Texte, und Texte auf Fotos werden je nach ihrer Lesbarkeit möglicherweise erkannt oder auch nicht.
Suche
Bei der Suche zeigt Ihnen die Anwendung, welche Notizen, aber auch welche Anhänge mit der Suchanfrage übereinstimmen. In diesem Fall wird oben in der Notiz, die die Anlage(n) enthält, ein Banner angezeigt:
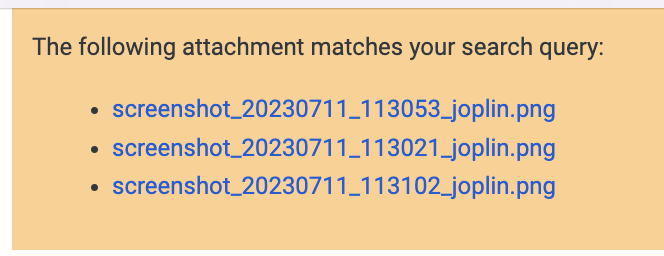
Die Suche in OCR-Text ist auf dem Desktop und der mobilen App aktiviert.
OCR-Text anzeigen
Mit der Anwendung können Sie den OCR-Text eines Bildes anzeigen. Klicken Sie dazu mit der rechten Maustaste auf einen PDF-Link oder ein Bild und wählen Sie "OCR-Text anzeigen". Dadurch wird eine neue Textdatei mit diesem OCR-Text erstellt und in Ihrem Texteditor geöffnet.

Erstverarbeitung
Die Bearbeitung von Bildern und PDF kann ressourcenintensiv sein, vor allem wenn Sie viele Anhänge haben. Wenn die Funktion zum ersten Mal aktiviert wird, wundern Sie sich also nicht, wenn die CPU-Auslastung von Joplin höher als gewöhnlich ist. Sobald der erste Scan aller Anhänge abgeschlossen ist, läuft alles wieder normal. Später wird jede Datei, die Sie anhängen, schnell und unauffällig gescannt.
Offline zuerst
Wie immer ist Joplin zunächst offline, was bedeutet, dass auch die OCR offline erfolgt, ohne dass eine Internetverbindung erforderlich ist und, was noch wichtiger ist, ohne dass Ihre privaten Daten in eine Cloud eines Drittanbieters hochgeladen werden müssen. Der Nachteil ist die oben erwähnte anfängliche Nutzung der Ressourcen Ihres Computers, aber wir glauben, dass sich dies lohnt, um eine vollständige Offline-Unterstützung zu ermöglichen.
Plug-in-System
OCR ist eine Technologie, die sich insbesondere mit den jüngsten Fortschritten im AI und im großen Sprachmodell (LLM) rasant weiterentwickelt. Daher ist Joplin OCR als Plug-in konzipiert. Wir werden die bestehenden Open-Source-OCR-Technologien beobachten und gegebenenfalls zu einer anderen wechseln, wenn dies sinnvoll ist, oder mehrere Technologien unterstützen.
In einigen Fällen kann es außerdem sinnvoll sein, eine cloudbasierte Lösung zu verwenden oder sich einfach mit Ihrem selbst gehosteten oder intranetbasierten Server für OCR zu verbinden. Das derzeitige System ermöglicht dies durch das Schreiben spezifischer Treiber für diese Dienste.
Diese plug-in-fähige Schnittstelle ist in der Software vorhanden, wird derzeit jedoch nicht angezeigt. Wir werden dies je nach Feedback und möglichen Anwendungsfällen tun. Wenn Sie einen bestimmten Anwendungsfall im Sinn haben oder ein Problem mit dem aktuellen OCR-System feststellen, teilen Sie uns dies bitte im Forum mit.
Benutzerdefinierte OCR-Sprachdaten-URL
Nach der Aktivierung von OCR lädt Joplin Sprachdateien von https://cdn.jsdelivr.net/npm/@tesseract.js-data/. Diese URL kann unter Einstellungen > Allgemeines > Erweiterte Einstellungen anzeigen > "OCR: Sprachdaten-URL oder -Pfad" angepasst werden. Dieser URL oder Pfad sollte auf ein Verzeichnis mit einer .traineddata.gz-Datei für jede Sprache verweisen, die für OCR verwendet werden soll. Nach dem ersten Download werden Sprachdateien zwischengespeichert.
Zum Beispiel, um OCR auf einem Computer ohne Internetzugang zu verwenden:
- Übertragen Sie die
.traineddata.gz-Dateien für die Sprachen, die OCRed werden.- Englisch: https://cdn.jsdelivr.net/npm/@tesseract.js-data/ger/4.0.0_best_int/eng.traineddata.gz
- Französisch: https://cdn.jsdelivr.net/npm/@tesseract.js-data/fra/4.0.0_best_int/fra.traineddata.gz
- Im Allgemeinen können trainierte Daten unter „https://cdn.jsdelivr.net/npm/@tesseract.js-data/[Sprache]/4.0.0_best_int/[Sprache].traineddata.gz“ abgerufen werden, wobei „[Sprache]“ durch „eng“, „fra“, „chi_sim“, „deu“, „spa“ oder einen der anderen unterstützten Sprachcodes ersetzt werden sollte.
- Übertragen Sie die
.traineddata.gz-Dateien auf den Offline-Computer. - Verschieben Sie alle Dateien in das gleiche Verzeichnis (z.B.
C:\Users\User\Documents\joplin-ocr-data\). - In Joplin öffnen Sie die Einstellungen > Allgemein > erweiterte Einstellungen anzeigen.
- Setzen Sie OCR: Sprachdaten-URL oder -Pfad" auf den Dateipfad des Verzeichnisses mit Trainingsdaten.
- Dies sollte der Pfad zum Verzeichnis sein, das in Schritt 3 ausgewählt wurde.
- Klicken Sie auf "Anwenden".
- Aktivieren Sie OCR.
Um vorhandene zwischengespeicherte Sprachdaten zu ersetzen, klicken Sie auf "Cache löschen und Sprachdateien neu herunterladen".