Reconnaissance optique des caractères (OCR)

![]()
![]()

La reconnaissance optique de caractères (OCR) consiste à transformer une image contenant du texte en un format que la machine peut interpréter. Lorsque vous numérisez un document texte, l'ordinateur le stocke comme un fichier d'image, empêchant l'édition directe de texte ou la recherche. L'OCR permet la conversion de l'image en texte.
Activation de la ROC
L'OCR doit être activée par défaut. Si ce n'est pas le cas, vous pouvez l'activer à partir de l'écran de configuration, dans la section "Générale". Une fois que vous aurez fait cela, Joplin va scanner vos images (PNG et JPEG) et les fichiers PDF pour extraire les données de texte.
La numérisation de documents n'est disponible que sur l'application de bureau car il s'agit d'un processus relativement gourmand en ressources. L'application mobile aura accès à ces données OCR par synchronisation.
Pour l'instant, la ROC est fiable lors de la numérisation de textes imprimés, de PDF en particulier, ou d'images où le texte est clair, comme les captures d'écran. Actuellement, nous ne prenons pas en charge le texte manuscrit et le texte sur les photos peut être reconnu ou non selon la clarté de son contenu.
Recherche en cours
Lorsque vous effectuez une recherche, l'application sera en mesure de vous indiquer quelles notes mais aussi quelles pièces jointes correspondent à la requête. Dans ce cas, une bannière sera affichée en haut de la note contenant les pièces jointes:
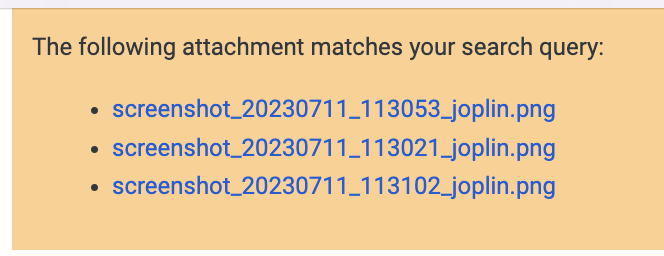
La recherche dans le texte OCR est activée sur le bureau et l'application mobile.
Affichage du texte OCR
L'application vous permet de visualiser le texte OCR associé à une image. Pour ce faire, cliquez avec le bouton droit de la souris sur un lien ou une image PDF et sélectionnez "Voir le texte de la ROC". Cela créera un nouveau fichier texte avec ce texte OCR, et l'ouvrira dans votre éditeur de texte.

Traitement initial
Le traitement des images et des PDF peut être intensif en termes de ressources, surtout si vous avez beaucoup de pièces jointes. Ainsi, la première fois que cette fonctionnalité est activée, ne soyez pas surpris si l'utilisation du processeur Joplin est plus élevée que d'habitude. Une fois que le balayage initial de toutes vos pièces jointes est terminé, cela reprendra la normale. Plus tard, chaque fois que vous attachez un fichier, il sera scanné rapidement d'une manière qui n'est pas remarquable.
Déconnecté en premier
Comme toujours, Joplin est d'abord hors ligne, ce qui signifie que l'OCR arrive également hors ligne sans avoir besoin d'une connexion internet et, plus important encore, sans avoir à transférer vos données personnelles dans un nuage tiers. L'inconvénient est l'utilisation initiale susmentionnée des ressources de votre ordinateur, mais nous pensons que cela vaut la peine d'activer le support hors ligne complet.
Système branché
La ROC est une technologie qui évolue rapidement, en particulier avec les progrès récents dans le domaine de l’IA et du grand langage (LLM) en particulier. En tant que tel, Joplin OCR est conçu pour être branchable. Nous surveillerons les technologies OCR open source existantes et nous pourrons basculer vers une autre technologie si cela a du sens, ou fournir une prise en charge pour plusieurs personnes.
De plus, dans certains cas, il peut être judicieux d'utiliser une solution basée sur le cloud, ou simplement de se connecter à votre serveur auto-hébergé ou intranet pour OCR. Le système actuel le permettra en écrivant des pilotes spécifiques pour ces services.
Cette interface branchable est présente dans le logiciel mais n'est pas exposée actuellement. Nous le ferons en fonction des commentaires que nous recevons et des cas d'utilisation potentiels. Si vous avez un cas d'utilisation spécifique en tête ou si vous remarquez un quelconque problème avec le système OCR actuel, n'hésitez pas à nous le faire savoir [sur le forum](https://discours. oplinapp.org/).
URL des données de la langue OCR personnalisée
Après avoir activé OCR, Joplin télécharge les fichiers de langue à partir de https://cdn.jsdelivr.net/npm/@tesseract.js-data/. Cette URL peut être personnalisée dans les paramètres > Avancé > "OCR: URL ou chemin de données de la langue". Cette URL ou ce chemin devrait pointer vers un répertoire avec un fichier .traineddata.gz pour chaque langue à utiliser pour OCR. Après le premier téléchargement, les fichiers de données de langue sont mis en cache.
Par exemple, pour utiliser la ROC sur un ordinateur sans accès à internet :
- Transférez les fichiers
.traineddata.gzpour les langues qui seront OCRed.- Français : https://cdn.jsdelivr.net/npm/@tesseract.js-data/fra/4.0.0_best_int/fra.traineddata.gz
- Français : https://cdn.jsdelivr.net/npm/@tesseract.js-data/fra/4.0.0_best_int/fra.traineddata.gz
- En général, des données formées peuvent être obtenues sur
https://cdn.jsdelivr.net/npm/@tesseract.js-data/[language]/4.0.0_best_int/[language]. raineddata.gzoù[language]doit être remplacé pareng,fra,chi_sim,deu,spa, ou un des autres codes de langue supportés.
- Transférez les fichiers
.traineddata.gzvers l'ordinateur hors ligne. - Déplacer tous les fichiers dans le même répertoire (par exemple
C:\Users\User\Documents\joplin-ocr-data\). - Dans Joplin, ouvrez les paramètres > Général > Avancé.
- Définissez "OCR: URL ou chemin des données de la langue" sur le chemin du fichier du répertoire avec les données de formation.
- Ce devrait être le chemin vers le répertoire sélectionné à l'étape 3.
- Cliquez sur "Appliquer".
- Activer OCR.
Pour remplacer les données de langue en cache existantes, cliquez sur "Vider le cache et re-télécharger les fichiers de données de langue".